



#EffetCapital : le dernier challenge technique d’Ekwateur
Lors d’une belle matinée de janvier, tombe la neige et une bonne nouvelle : on va passer dans l’émission « Capital » de M6, et cela grâce au travail de Julien (cofondateur d’Ekwateur) et de notre agence de presse !
26 avril 2018
Lecture 6 mn
Réflexion post annonce
Le tournage est prévu courant février pour un passage dans l’émission du dimanche 11 Mars. Passé le moment agréable d’euphorie collective pour notre Startup, on se dit tous-tes que maintenant on a du pain sur la planche (et ce n’est pas comme si on n’en avait pas avant). Voici comment l’on s’est préparé à l’ #effetCapital chez Ekwateur.
Il m’est arrivé par le passé de gérer des pics de connexions côté ‘serveur back-end’ par des sollicitations d’applications emails, pour la TV sur mobile, des matchs de foot, ou la quinzaine de Roland-Garros. En parlant de RG (comme on dit dans le jargon), lorsqu’un joueur français arrive dans les derniers carrés, ça peut vite chauffer côté serveur d’application et tout doit fonctionner ! Pas le droit à l’erreur. La tension était au maximum et il n’y avait pas de porte de sortie. La montée en charge était rapide dès le début de la rencontre, avec des pics sur toute la durée du match. Les données devaient être à jour en temps réel pour le score du match, qui est au service, le flux vidéo, les commentaires…
Pour revenir à nos oignons, on est ici dans un autre cas de figure : le site Ekwateur et la souscription en ligne pour réaliser des devis de fourniture de gaz vert et d’électricité renouvelable. Tout doit être fonctionnel pour le pic de connexion et ce durant toute la durée de l’émission Capital, car Ekwateur est en première partie de l’émission (à partir de 21h). Le Cloud nous apporte une souplesse et un confort incomparable au regard d’une infrastructure ‘in-house’ moins facilement évolutive (oui, je ne voulais pas dire scalable) que j’avais pu utiliser auparavant.
1. Phase d’analyse et de benchmark des applications
Je vais maintenant décrire comment nous avons procédé pour réaliser et préparer nos environnements aux tests de performances.
Premièrement, j’ai établi une cible du nombre de visiteurs sur le site. Tous les benchmarks et la cible (tests de performance) dépendent de cela. J’ai donc pris pour base le nombre de téléspectateurs de l’émission M6 Capital sur les audiences moyenne de l’émission, soit 2,3 Millions de téléspectateurs. L’objectif étant que 10% de ces téléspectateurs viennent visiter notre site, donc cela donne un pic maximum de 230 000 visiteurs. Ensuite, j’ai regardé page par page les différents services appelés et établi mes projections sur ces services : sur le devis et les différentes étapes de souscription, les formulaires de newsletters… J’ai ensuite pris le pic, regardé le nombre de requêtes lors d’un précédent pic de visites puis avec une règle de trois, j’ai extrapolé mes projections pour avoir un nombre de requêtes par seconde et par minute (rpm : requests per minutes), des indicateurs intéressants pour les Load Balancers notamment.
Deuxièmement, j’ai optimisé le parcours utilisateur afin de définir le périmètre des benchmarks et identifier les points de contention entre nos applications.
Les benchmarks permettent aussi de régler les timeouts inter-applicatifs et d’affiner le potentiomètre pour le nombre de connexions en parallèle que l’application peut traiter (‘thread’).
L’architecture applicative de nos serveurs Front – se compose de 3 sites sur un serveur web Apache avec des redirections croisées, un CMS, des frameworks PHP et du PHP. Nous en avons profité pour optimiser les temps d’affichage des pages du site, et optimiser la configuration du serveur web via un passage sur Nginx.
De l’art de réaliser des benchs : il est très difficile voire même impossible de simuler un cas de production réel. Et que dire de la simulation de la montée en charge rapide du trafic sur les serveurs comme cela sera le cas le jour J. Mais l’objectif avec nos tests est de s’en rapprocher au maximum telle l’asymptote sur un graphique.
Pour notre part, nous avons utilisé l’outil open source Locust qui a l’avantage d’être très simple d’utilisation, avec des machines injectrices puissantes sur notre compte AWS (Amazon Web Services) pour simuler un parcours client sur le site.
Troisièmement, nous avons fait le choix d’exclure volontairement certaines parties de notre application en les cachant temporairement pendant le pic. Car une page non optimisée peut à elle seule faire tomber tout le site (dépendant de l’architecture qui a été mise en place).
2. Préparation de l’infrastructure
La plupart des téléspectateurs regardant l’émission ont entre les mains leur téléphone portable ou une tablette. D’après Médiamétrie, 43,7% des visites sur le web sont faites depuis un téléphone mobile, tandis que 9% proviennent de tablettes en 2017. Moins d’une visite sur deux provient d’un ordinateur. Ces « mobinautes » arrivent donc en masse et en quelques secondes sur la page d’accueil du site dès l’apparition du nom de la société dans l’émission.
Soignez donc vos points d’entrées ! C’est la homepage qu’il faut veiller à optimiser au maximum et en priorité. Cela nous amène donc à détailler en quelques lignes l’architecture IT de notre plateforme hébergée sur le Cloud AWS.
Cloud Front :
Une visibilité comme celle-ci est le moment idéal pour accélérer des chantiers que nous avions identifié sur notre infrastructure avec la Mise en place de CloudFront pour du cache et la possibilité de mise en place d’un WAF (Web Applicative Firewall).
Les ELB (Elastic Load Balancer) :
Nous n’avons en général pas à se soucier des ELB dans l’architecture des services sur AWS. Sauf en cas de fort trafic soudain. Il faut dans ce cas contacter le support Amazon en amont (+ de 48 heures en avance) pour leur demander un préchauffage (prewarm) des ELB. Dans notre cas, nous avons fait une demande plus d’un mois à l’avance et nous avons bien fait car AWS nous a demandé de préciser un certain nombre d’éléments pour le préchauffage des ELB. Ce préchauffage permet concrètement de multiplier les points d’entrées de vos ELB en ayant plusieurs adresses IP accessibles. Vous pouvez les voir en utilisant la commande ‘dig’.
Limite du nombre de serveurs :
J’ai également demandé une augmentation du nombre limite de serveurs sur notre compte AWS sur nos environnements de préproduction et de production (car il y a une limite par type de serveurs).
Cela permet de réaliser des benchmarks sur l’environnement de préproduction et de dérouler tout le test à blanc sur cet environnement. Et ensuite, comme nous l’avons réalisé, de jouer toute la procédure en production en amont, afin de lever un loup non repéré.
Chronogramme des événements pour le jour J :
Nous avons déroulé un test à blanc pour valider le chronogramme des événements sur la production :
- Nombre de serveurs cible
- Tirs de benchs pour simuler les connexions des clients / utilisateurs
- Préchauffage de vos instances
- Rôle de chacun pour valider leur responsabilité le jour J : répondre au chat, répondre sur les réseaux sociaux,…
3. La gestion des imprévus
Toujours prévoir un plan B
Autrement dit, un plan de secours, le service minimum que les internautes vont pouvoir parcourir sur votre site, ou même un serveur de débordement contenant un message spécifique pour les inviter à revenir plus tard dans le cas où il y aurait trop de trafic.
Pages d’erreurs personnalisées
La pire expérience qui pourrait arriver pour un client ou prospect internaute, serait d’arriver sur une page d’erreur 503 (50X) vide avec dans la barre d’adresse https://ekwateur.fr. #BadBuzz
Nous avons donc personnalisé nos pages d’erreurs serveur ! Pages d’erreurs personnalisées qui s’affichent dans le cas où le service ne fonctionnerait plus.
Et comme on regorge d’idées chez Ekwateur, à la suite d’une phrase que j’ai pu prononcer lors d’une réunion de préparation « si notre serveur est dans les choux », nous avons pris la balle au bond et développé une page d’erreur sympathique.

Le but étant bien évidemment que personne ne puisse voir cette page. Dans notre cas, il a pu arriver que certains visiteurs du site arrivent sur cette page qui a du coup fait le buzz sur les réseaux sociaux.

Un audit, car on n’est jamais assez prévoyant
Nous avons fait un petit refresh avec un audit de sécurité sur nos applications, on ne sait jamais car les optimisations réalisées et / ou la visibilité que l’on peut acquérir suite à l’émission peut éventuellement ramener son lot de hackers ou d’utilisations non conventionnelles de nos applications.
4. Le jour J est arrivé / le D day
Et là, c’est le drame :
Comme le nez au milieu de la figure, mais c’est passé, et personne ne l’a vu. Le souci de dernière minute qui m’a rendu chèvre : c’est le « ç » : le « c cédille » à « ci-dessous » ! « çi-dessous » écrit en tête de page ! Une faute d’orthographe sur le formulaire de souscription . La certitude que la twittosphère se déchaînerait sur nous en sarcasmes et blagues douteuses. Après relivraison de la version corrigée à la dernière minute, nous avons pu passer au lancement de notre batterie de serveurs Front et procéder aux tirs de benchmarks de préchauffage sur nos serveurs (nécessaire pour créer le cache).
Les yeux rivés sur différents écrans : l’écran TV pour voir apparaître l’affichage du nom de la société ekwateur.fr dans l’émission M6 Capital, sur un des écrans du PC sur Google Analytics pour voir le trafic et le parcours des utilisateurs sur le site et en parallèle sur les courbes techniques et le monitoring des différents serveurs applicatifs composants l’architecture de la plateforme IT. Nous aimerions bien avoir plusieurs paires d’yeux à ce moment-là 😉.
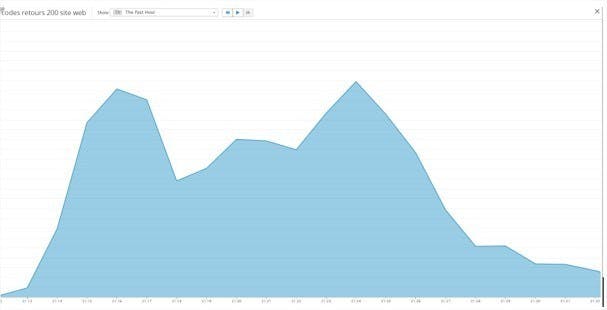
Le pic des connexions arrive en moins de 3 minutes. Il est bien passé. Très peu de retours 50X et 40X, donc énormément de retour http 200, et c’est bien cela que nous voulons voir !
Les internautes naviguent sur le site et passent quelques 3 minutes 30 sur nos pages… Puis ça repart vers un autre pic un peu plus élevé, qui passe bien lui aussi. Puis petit à petit, le trafic redescend, le reportage est terminé, et c’est l’heure de la pub.
Nous pouvons maintenant souffler et profiter d’une petite coupe de champagne
Ekwateur a absorbé l’effet Capital !!
Par Doctor Who, Ekwateur
PS : si dans ce texte vous avez trouvé le loup, la chèvre et le chou, vous avez gagné 150 kWh avec le code EKW000638585
Remerciements :
Scaleo, experts et partenaire AWS nous accompagne depuis le début. Dès la conception et l’architecture de nos services et la mise en œuvre de nos applications Ekwateur sur l’infrastructure cloud d’AWS. Merci tout particulièrement à Marc et Alexandre qui ont fait partie intégrante de l’équipe en ayant serré les dents avec nous jusqu’au jour J.
Merci à l’agence de presse L’agence RP pour leur préparation et accompagnement avec l’équipe de M6.
Merci à la société Vaadata pour leur réactivité pour réaliser l’audit de sécurité.
Merci à l’équipe Ekwateur et la mobilisation de chacun !
Et enfin, merci à M6 et l’équipe de tournage.




