


Tests de performance et importance de la randomisation
En ce lointain passé où les Français ne connaissaient pas le terme de « COVID », il était prévu qu’Ekwateur passe dans une émission de M6. Mais le mois de mars est arrivé et, avec lui, la pandémie. L’émission M6 fut annulée, tout comme bien d’autres activités. Néanmoins, certaines choses furent conservées et nos efforts pour nous améliorer (nous et nos applications bien aimées) ne furent certainement pas jetés. C’est ainsi que nous utilisâmes Gatling et mirent en place des tests de performances. Mais avant de parler de Gatling (nous verrons ça dans un prochain article), parlons de randomisation
22 juin 2020
Lecture 4 mn
Qu’est-ce que la randomisation et pourquoi est-ce important ?
« Randomisation » vient du terme anglais « random » qui veut dire « aléatoire ». « Randomizer » consiste donc à « rendre aléatoire ». Dans le cas de tests de performances, ce sont les paramètres envoyés à une requête que l’on va « rendre aléatoire ». Mais pourquoi est-il important de faire cela ?
Il y a deux raisons principales :
Premièrement, une fonction peut ne pas mettre le même temps à s’exécuter en fonction des paramètres qu’on lui passe. Ainsi, si vous envoyez toujours les mêmes paramètres à votre méthode, vous pourriez vous retrouver avec un temps de réponse biaisé.
Prenons un exemple pour illustrer cela :
Imaginons que vous deviez vous rendre d’un point A à un point B et que vous vouliez savoir quel est le temps moyen que cela prend aux personnes de manière générale. Il y a trois chemins possibles et avec eux trois moyens de transport différents. En outre, la météo varie et peut donc jouer sur votre temps de transport.
Si vous avez un vélo, vous prenez le chemin 1 qui va vous prendre 45 minutes par beau temps et 1 heure par mauvais temps avec un vent de face.
Si vous avez une voiture, vous prenez le chemin 3 qui va vous prendre 30 minutes, peu importe les conditions météo.
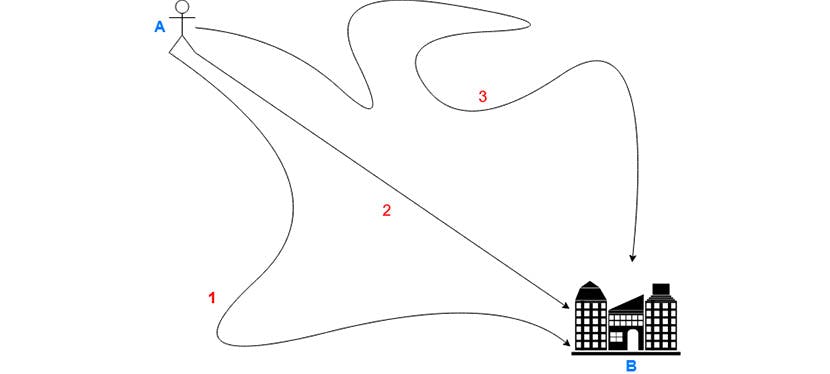
Si vous n’avez ni l’un ni l’autre, vous prenez le chemin 2 (le plus court en distance), chaussez vos baskets, et ce chemin va vous prendre 3 heures par beau temps et 5 heures par temps de pluie.
Si vous voulez savoir quel est le temps moyen pour aller du point A au point B, il vous faut prendre en compte le fait qu’il y a trois chemins différents. Si vous vous contentez de tester le chemin 1 avec des types de temps différents, vous aurez complètement négligé le fait que certaines personnes n’ont pas de vélo (ni voiture) et que, de fait, se rendre au point B est bien plus long pour elles.
Ainsi, vous avez bien répondu à une question : « quel est le temps moyen que cela prend pour aller du point A à B lorsque l’on a un vélo », mais cela ne répond pas à votre question initiale qui est de savoir « quel est le temps moyen que cela prend pour aller de A à B (peu importe le moyen de transport) ».
Vous venez de prendre conscience que tous les chemins menant au point B ne sont pas équivalents. Vous allez donc prendre soin de tester en utilisant vos trois chemins. Cependant, êtes-vous sûr que ces chemins sont utilisés de manière proportionnelle ? Admettons que 80% des personnes utilisent la voiture, 15% le vélo et 5% la marche. Si vous voulez que vos résultats soient les plus proches de la réalité possible, il est fortement conseillé de prendre en compte ces spécificités dans votre processus de randomisation.
La prédiction de chemin
Changeons maintenant de modèle et imaginons que, peu importe le chemin que vous preniez pour aller au point B, le temps que cela prendra est significativement le même. Dans ces conditions, peut-être pensez-vous que la randomisation est inutile ? Détrompez-vous !
Afin d’améliorer leur performance, les programmes informatiques utilisent ce que l’on appelle de la « prédiction de chemin ».
Imaginions que Bob veuille partir à la cueillette aux champignons. Il connaît deux lieux : l’un où il y a très souvent des champignons et l’autre où il n’y en a que lorsque le premier lieu n’en a pas.
Bob veut ramasser le plus de champignons possible avant que la nuit tombe. Cependant, à son arrivée à l’intersection des deux chemins, Bob ne sait pas quel chemin mènera aux champignons (il sait cependant que le chemin de droite est celui qui mène le plus souvent aux champignons).
Bob a deux solutions :
- Attendre que son amie Alice lui téléphone pour lui dire où sont les champignons
- Ou, afin de tenter de gagner du temps, prendre l’un des deux chemins espérant qu’il aura choisi le bon
Dans ces conditions, votre programme (Bob) choisira de tenter de gagner du temps prenant l’un des deux chemins. Grâce à sa mémoire, votre programme (et Bob) savent que c’est le chemin de droite qui est le plus souvent le bon. Bob (et votre programme) vont donc « prédire » que, cette fois encore, le chemin de droite sera le bon (mais ils peuvent se tromper). Ils viennent de réaliser une « prédiction de branche ».
À noter que, dans la plupart des programmes, réaliser une prédiction de chemin ne fera pas perdre du temps en cas d’erreur. Cela n’aura juste pas permis d’en gagner.
Vous savez maintenant ce qu’est une « prédiction de chemin ». Expliquons désormais en quoi cela est un problème lors d’un test de performance.
Comme dit plus haut, la prédiction de chemin permet de gagner du temps. Ainsi, si vous effectuez un test de performance en envoyant toujours les mêmes paramètres, votre programme utilisera toujours le même chemin. Et grâce à la prédiction de chemin, il s’exécutera plus rapidement que la normale. Or, vous voulez connaître (entre autres) la vitesse moyenne d’exécution de votre programme et non sa vitesse d’exécution optimale.
En outre, il est fort probable que votre programme utilise des caches. Ainsi, utiliser uniquement des données identiques à chaque appel ne fera qu’augmenter la vitesse d’exécution de votre programme. Sans une bonne randomisation, vous vous retrouverez donc avec des résultats beaucoup plus optimistes que la réalité.
C’est là toute l’importance de la randomisation : éviter d’avoir des résultats biaisés et trop optimistes.



